优于o1预览版,推理阶段KV缓存缩减一半,LightT
日期:2025-03-12 08:42 浏览:

LLM 在天生 long CoT 方面展示出惊人的才能,比方 o1 已能天生长度高达 100K tokens 的序列。但是,这也给 KV cache 的存储带来了严格挑衅。为应答这一困难,“hybrid model” 成为了一条备受存眷的可行门路:它在尺度 transformer 的局部层中引入更高效的留神力机制(如 RNN 或 sliding window attention),以替换原有的留神力层。近期的研讨(如 minimax-01、gemma2 等)曾经充足验证了这种混杂模子的无效性,但现在仍然须要重新练习,尚未呈现能够直接轻量级迁徙曾经练习好的 dense transformer 模子到 hybrid model 的计划。咱们盼望提出一种简练高效的方式,将欧洲杯足球曾经预练习实现的 dense transformer 模子顺遂转换为 hybrid models。为此,咱们提出了 LightTransfer,这一思绪源于一个要害察看:现有模子中存在大批浮现 “lazy” 特征的冗余层 [1]。因而,一个直不雅的主意就是将这些冗余层调换为仅需常数巨细 KV cache 的 streaming attention,从而无需保护完全的 KV cache,将 dense Transformer 改变为更高效的 hybrid model。
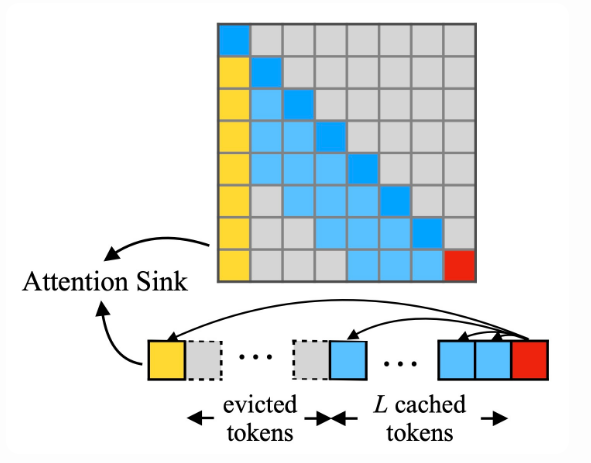

名目主页:https://sites.谷歌.com/view/lighttransferHuggingface 模子:cxdu/QwQ-32B-LightTransfergithub 代码:https://github.com/sail-sg/LightTransLightTransfer-Train1) 方式LightTransfer 的方式十分直接:咱们先在练习集上跑一遍 benchmark,辨认出最 “lazy”,也就是 lazy ratio 最高的 50% attention 层,而后将这些层调换为 streaming attention。lazy ratio 用来权衡模子在第 (i) 层的留神力调配:它统计了来自 Query 对初始跟近来 key 的留神力权重之跟,数值越高就代表该层的留神力越会合在这些 key 上,也就越 lazy。lazy ratio 的详细界说如下:
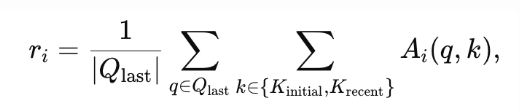
此中:表现最后一局部的查问(query)聚集;

分辨表现初始与近来局部的键(key)聚集;为在第 i 层从查问 q 到键 k 的留神力权重。当值越高,阐明第 i 层对这些键的存眷度越会合,也就越“lazy”。QwQ 中每层的 lazy ratio 散布如下:
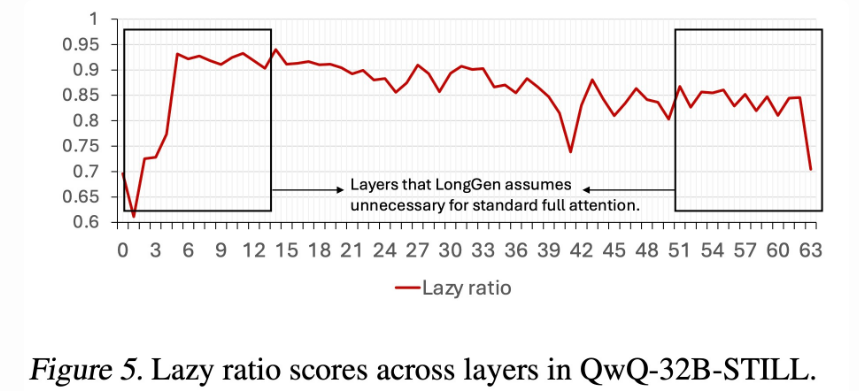
2) 试验成果咱们的重要试验工具是 o1 类的长 CoT 天生模子。因为 QwQ 并未公然其练习数据,咱们遵守 STILL [2] 的计划,应用与其完整雷同的练习设置(包含数据集、练习参数以及以 Qwen2.5-32B-Instruct 作为出发点),独一的差异在于,咱们将 50% 的层换成 streaming attention。如许就能在推理阶段明显缩减近一半的 KV cache。